



Wavelets I - From Filter Banks to the Dilation Equation
This is the first in what I hope will be a series of posts about wavelets, particularly about the Fast Wavelet Transform (FWT). The FWT is extremely useful in practice and also very interesting from a theoretical point of view. Of course there are already plenty of resources, but I found them tending to be either simple implementation guides that do not touch on the many interesting and sometimes crucial connections. Or they are highly mathematical and definition-heavy, for a non-mathematician (such as me) it might be difficult to distill the important ideas. I will try to cover all necessary aspects as clearly as possible, so that we get to a point where we can work confidently and creatively with these algorithms.
Here we will start with the implementation of the FWT, which is easily done with a cascaded filter bank. From there we develop the corresponding wavelet properties and get to the maybe most important aspect of the Multi-Resolution Analysis (MRA), namely the dilation and wavelet equations. I think this is a reasonable and intuitive approach, although I have not seen it like that anywhere else. My assumption is that you know the very basic principles of the continuous wavelet transform, digital filters and the Z-transform. I just want to mention that this is my first post of this kind in English and I would appreciate your comments if you find mistakes in this text or in the calculation, if something is unclear or if you have any kind of feedback or question!
Filter Banks
A finite impulse response (FIR) filter transforms a discrete signal by convolving it with a finite series of values :
The basic building block of our filter bank is shown in this graphic:
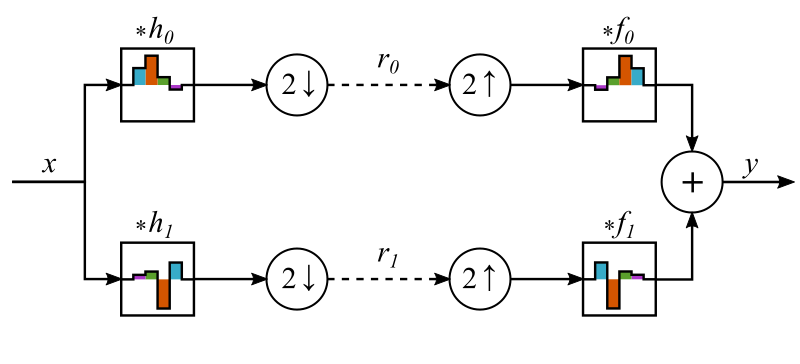
The input signal is split and fed into two different analysis filters and . These two signals are downsampled by a factor of two (i.e. all values with odd are deleted). Now we have an intermediate representation of the input signal, consisting of two different signals and , each with half the sample count. But if we do it right, since the total amount of samples remains the same, there could still be all information left from the input. To reconstruct the signal, the representations are now upsampled by a factor if two (a zero is inserted after each sample) and fed into the reconstruction filters and . Then the outputs of these filters are added together.
If possible, we want the output of this whole setup to be exactly the same as the input, except maybe a constant gain and delay, making it a perfect reconstruction (PR) filter bank. The simplest set of filters meeting this condition are the Haar filter: , , , . You can check it yourself by feeding a single impulse signal () into the filter bank and seeing that the output is still an impulse. Because of the linearity of the system this means that signals, since they are just a linear combination of many impulses, will be perfectly reconstructed.
Of course there are not just the Haar filters that yield a PR filter bank. Let’s look at the Z-transform of Figure 1:
More information is available here. Our PR condition, with gain and a delay of samples, in terms of the Z-transform is
As we see, there is no use for the second term in , i.e. the alias term proportional to . The easiest way to get rid of it is to set
- , which is equivalent to
- , which is equivalent to
To have everything nice and compact we set and to be a so-called conjugate quadrature filter (CQF) pair. Here this means is in reverse ( is the length of and must be even):
- , or
Now , and can be all expressed in terms of . An additional benefit is that and are orthogonal:
Equation combined with the PR condition becomes:
If we set and , we can write
This constraint is not quite as straightforward to translate for . Using the definition of the Z-transform we can write
Because it can’t depend on , has to be zero for . With , our perfect reconstruction constraint for is:
Which means has to be orthogonal to versions of itself shifted by an even number of samples. This orthogonality condition, in combination with , and is sufficient for creating a set of filters for a PR filter bank. A procedure for getting the coefficients with additional beneficial features will be explained in my next blog post.
As you can see, I use specific filters in the graphics. These are the filter coefficients of the Daubechies 4 (DB4) wavelet, each one in a different color.
You can check that they meet the condition. I picked these because of the manageable filter length of four, and their characteristic shape. My aim is to anchor the abstractions with some concrete elements and thus making it easier and more intuitive to grasp.
The representations and are themselves signals that can be fed into a similar filter bank module. We can do this an arbitrary number of times, resulting in more and more representations of coarser and coarser resolution.

Reconstruction works the same way. And if all filter bank modules reconstruct the signal perfectly, so does the whole cascade.

Multi Resolution Convolution
In this section we will concentrate on the filter. So let’s look at the upper half of Figure 2 (shaded in yellow). What has to happen to compute one sample, say the one with index 0, of the representation signal ? We can draw a graph describing the operation as a computational graph:
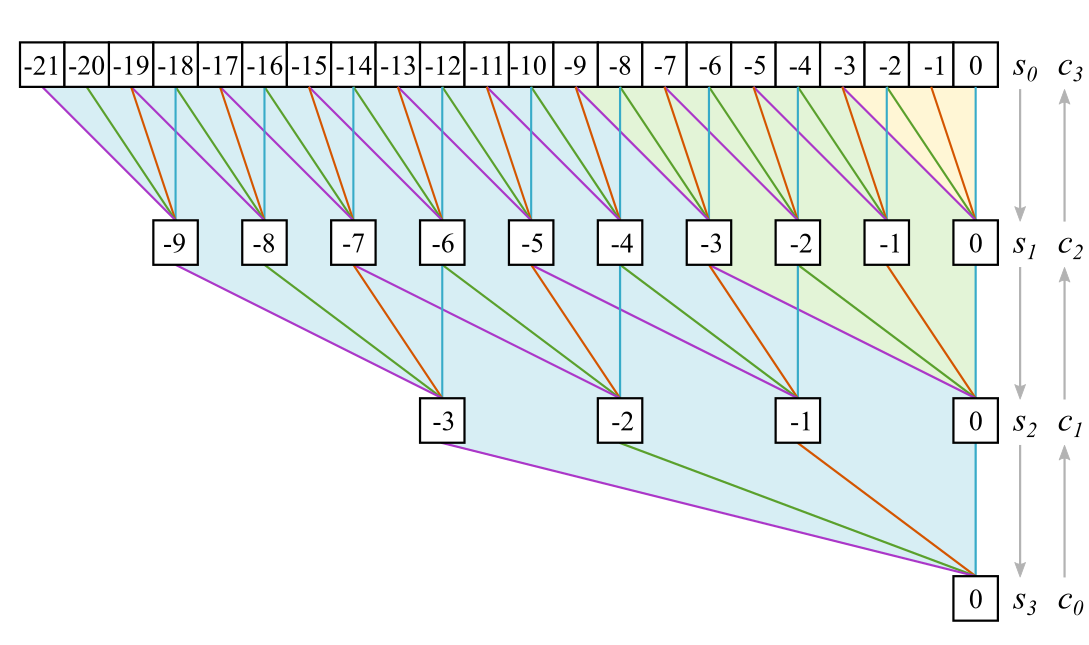
The white squares illustrate the signal at different representation states, which I have slightly renamed for convenience: and in general being the representation with subscript zeros, meaning the output of the th analysis filter . A colored line stands for a multiplication with the corresponding filter coefficient, following the specified convolution and downsampling procedure
It should be clear how the graph would look like if we added more layers and looked at the sample 0 of the innermost representation signal. The graph would grow upwards, getting denser and denser at the top, but the bottom part stayed the same, only the labels of the representations would change.
Technically, our topic is wavelets. At their core idea, wavelet representations do not build on one another. A scaled and shifted version of a wavelet is used always on the original signal, the cascading approach is just an implementation trick. This means for our filter bank it is also useful to examine how the direct link from the signal to every representation level looks like. For that, we have to look at Figure 4 in a different way: All the operations for generating the bottom sample 0 from the input signal - since they are all linear - can be combined into a single long filter , where is the number of considered representation stages. To get the coefficients of this combined filter, we look at all the paths connecting a square at the level to the bottom square. These paths all have colored segments. The coefficients corresponding to the color of the segments are multiplied and these products are added for each different path. Note that now the white squares don’t depict the signal in its various representations anymore, but the coefficients of the combined filter . For example, if we take , there are four paths to :
[-10]——[-5]——[-2]——[0][-10]——[-5]——[-1]——[0]
[-10]——[-4]——[-2]——[0]
[-10]——[-4]——[-1]——[0]
This results in a filter coefficient
The resulting factor is exactly how an input sample is scaled while traveling through the graph from top to bottom.
The efficient way to compute the coefficients for is working the way up the graph and using the following rule (all values of with non-integer indices are zero):
The length of the filter more than doubles for each subsequent level. To again get closer to the idea of wavelets, which are first defined at a certain size and then scaled, we do not want an ever growing discrete filter, but rather a function that ideally will be continuous at the limit. To achieve this, we have to introduce a re-parametrization of the filter: , where , which also means .
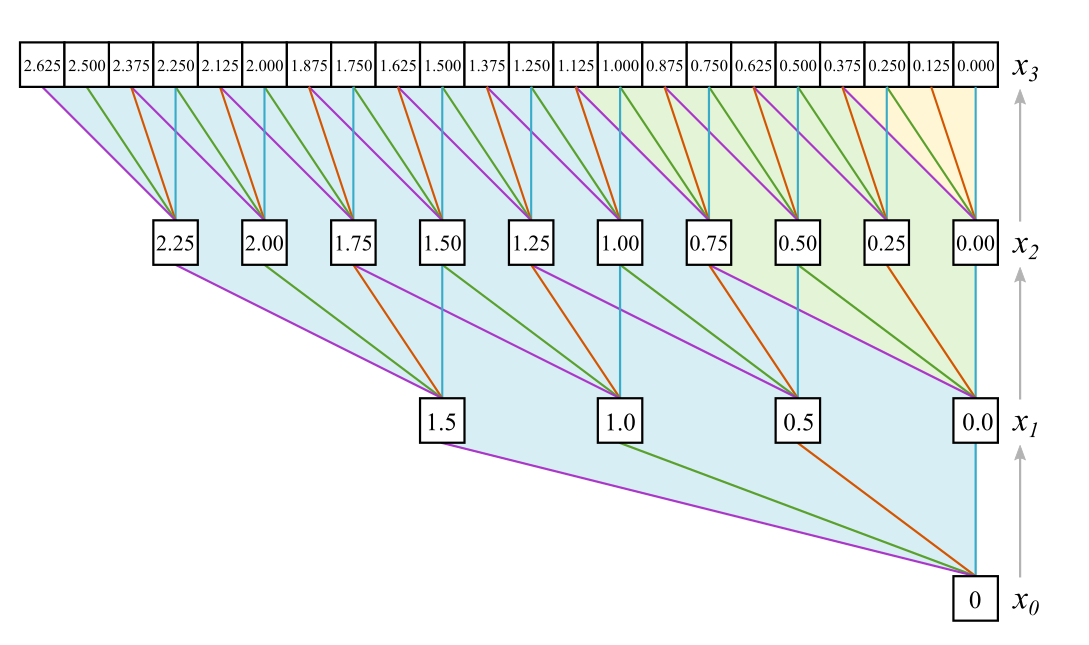
We have to adapt our construction progression for the filter functions :
Or when we set
We have to give this sequence a starting value, we use . Then has just the filter coefficients as values. The next graphic shows the first several levels of and the converged progression:
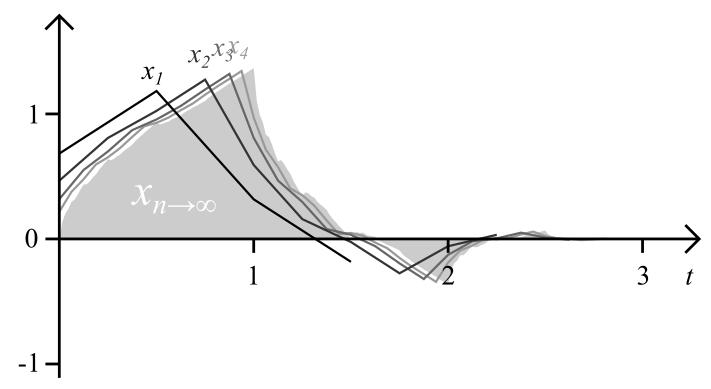
These are, in the sense of a discrete continuous wavelet transform, the actual “wavelets” used, for each representation a different one, although they converge quite quickly.
The Dilation Identity
The factor in prevents this progression from being elegantly expressed as a limit for . So we will try to find a better suited equivalent progression. The first step, calculating from , could also be achieved by , as we can easily see. This currently seems somewhat arbitrary, but let’s generalize this relation nevertheless to a construction progression of different function :
Notice that it has the same form as . I think this resemblance can be a bit misleading, as blurs the distinction between the filter bank implementation and the underlying mathematical framework of the MRA. Looking at the corresponding graph shows that the link between and is less obvious at it may seem at the first superficial glance:
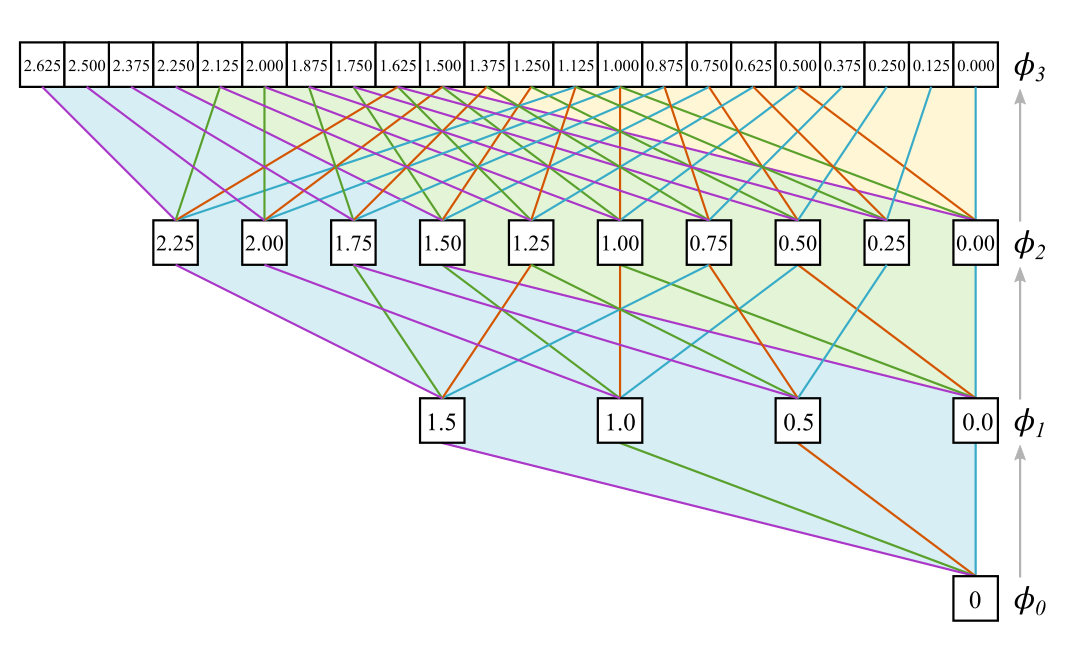
The connections are completely different from the previous graph, except for the first step. But the remarkable thing is that the paths connecting values of to have exactly the same color combinations as the graph. See for yourself! We can look again at , which is equivalent to our previous example . The paths connecting this node to are:
[1.250]——[1.50]——[1.0]——[0][1.250]——[1.50]——[0.0]——[0]
[1.250]——[0.50]——[1.0]——[0]
[1.250]——[0.50]——[0.0]——[0]
And with that we have
The order of the paths is jumbled, as are the colors of the path segments (those are in fact exactly reversed). But in the end they generate the same result. But while we can verify the identity for , this seems a bit magical and is nothing more than a nice observation. We need a proof that the identity holds for all .
Let’s start with our two progressions and :
We assume that . They are now interchangeable and we swap them.
Then we go back one more level and plug in the recursive step that defines or in terms of or .
As we see, the arguments of and on the right are the same. This means, if we additionally assume , then . In short:
If and , then
We have already seen that our assumptions hold for the first two levels, i.e. and . With that, as we showed, we have , and as a consequence of that , and so on for all . Therefore we have proved by induction that indeed:
The Dilation and Wavelet Equation
For , converges to a continuous function with support , where is the number of coefficients of , and (the support of a function is the interval where it is different from zero). Let’s call this function simply . This converged progression still has to hold the construction criterion:
This is the dilation equation, the workhorse in the theory of the FWT and MRA. And itself is the scaling function of the FWT, in our concrete examples the DB4 scaling function. The dilation equation says that the scaling function has a fractal self-similarity: it can be constructed of versions of itself, compressed by a factor of two, shifted and scaled by the coefficients.
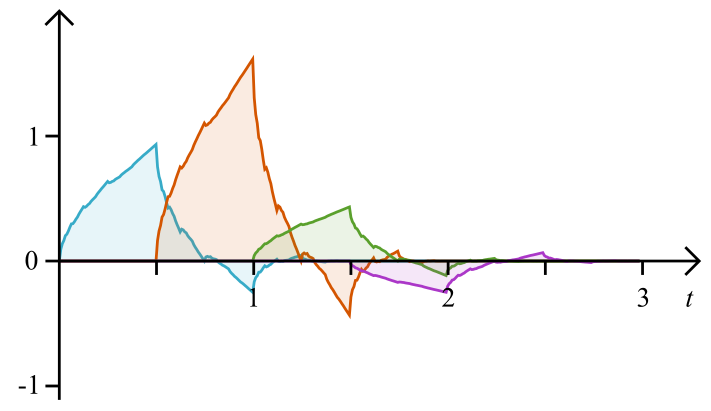
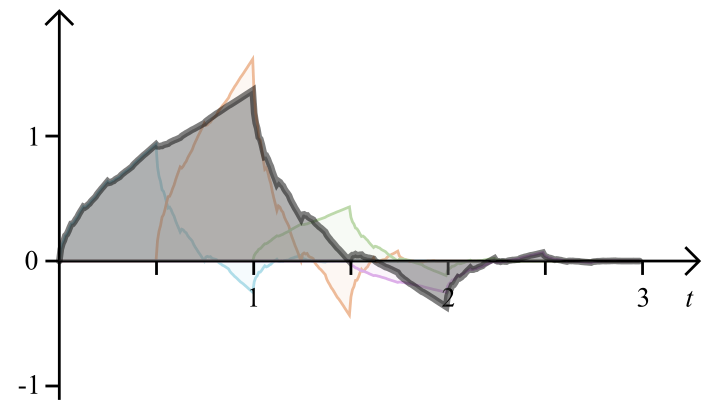
We of course have a way to approximate by iterating (1.12). This is called the cascading algorithm, and the iterations will, as we showed, look exactly like in Figure 6. While it is not possible to write the scaling function out explicitly, we can get can exact values by solving a system of linear equations derived from the dilation equation.
or
This system is homogeneous, meaning it has only zeros on the right side, and has no distinct solution. We have modify it slightly:
I have added the first and last equation together and added an additional constraint, namely that the sum of the four variables should be 1. This system can be solved and gives us the values of at the four integer positions. We plug these values in the dilation equation to get the values that lie exactly halfway between them and repeat this procedure. This way we have very quickly a large amount of exact values of .
We have not yet looked at the signal representations obtained with the filter, the in Figure 2. We cannot define something like a scaling function for , because the cascading algorithm does not converge for a highpass filter. But we can easily see what happens if we analyze a representation that itself was constructed with the scaling function (so basically one pass through the filter after infinitely many passes through ). For this we take the proof leading to and use it with adapted progressions:
The proof works just the same, and we can write:
This is the wavelet equation, defining the wavelet function of our FWT. According to the this equation, the wavelet function can also be constructed from compressed and scaled version version of , this time scaled by .


The thing last to show in this article is that not only and are orthogonal, which as we saw arises from , but also and :
First we used the linearity and shift invariance of the integration operator to group the function into multiple terms. Then we can see that the factors of all terms are zero, because of the relationship between and defined in .
Conclusion
We have seen the conditions - for the analysis filters and , as well as the synthesis filters and of a cascaded perfect reconstruction filter bank implementation of the FWT. Those are critical and sufficient to make it work. Then we have tried to look at this implementation from a wavelet point of view. For this we have introduced the identity , which then led to the dilation equation and wavelet equation . Those equations define the functions and in terms of the filters and .
The scaling function and the wavelet function give us a great analytic perspective of our algorithm. But it is important to remember that they are theoretical limits that never actually occur in a practical filter bank implementation of the FWT, not even as discretized or subsampled versions. This is a distinction from a discrete implementation of the continuous wavelet transform, where the scaled wavelets are explicitly used.
The fact that the actually (implicitly) used filters with finite vary from can be seen as a discretization artifact. A signal with higher sample rate uses a better approximation of at a certain scale, because it must have gone through more precedent filters to reach this level. If we could use the filter banks on a infinitesimally sampled signal, all filters would have had an infinite count of filters before them, making the effective filter be equal to .
This concludes my first article. I hope it was interesting for now, although it might not yet be clear how we can actually use these results. In the next blog post, however, I will explain how they can help us to design better filters with remarkable features.
Useful Resources
- Blatter, Christian: Wavelets - Eine Einführung (link to pdf, german)
- Fugal, D. Lee: Conceptual Wavelets
- Keinert, Fritz: Wavelets and Multiwavelets
- Rieder, Andreas: Wavelets - Theory and Applications
- Smith III, Julius O.: Spectral Audio Processing
- Strang, Gilbert: Wavelets and Dilation Equations: A Brief Introduction (link to pdf)
- Winkler, Joab A.: Orthogonal Wavelets via Filter Banks: Theory and Applications (link to pdf)
- Comments
- Write a Comment Select to add a comment
,
Thanks for your good work on the blog Wavelets 1 From Filter Banks to the Dilation Equation.
I'm the author of the book "Conceptual Wavelets in Digital Signal Processing" referred to above by my kind friend Rick Lyons (www.ConceptualWavelets.com). I also teach a short course for Applied Technology Institute (ATI) called Wavelets: A Conceptual Practical Approach. (http://www.aticourses.com/wavelets_conceptual_practical_approach.htm).
FYI, Rick Lyons and I have also co-authored The Essential Guide to Digital Signal Processing for Prentice Hill and Im writing another book with a working title Digital Signal Processing Practical Techniques, Tips, and Tricks. I also teach this course for ATI. See (http://aticourses.com/Digital_Signal_Processing_Essentials_Advanced_Processing.html). See my website www.dspbook.com for further information on these books and courses.
Besides Conceptual Wavelets I would also add Introduction to Wavelets and Wavelet Transforms by Sidney Burrus to your list of useful resources.
In your blog you touched on many of the same interesting ideas that are explained in the ATI course and in my Wavelets book. Specifically:
Fast Wavelet Transforms in general: See Chapter 4 The Conventional (Decimated) DWT Step-By-Step
Dilation Equation, z-transforms, Fractal construction: See Chapter 13 Relating Key Equations to Conceptual Understanding
Multi-Resolution Analysis: See Chapter 10 Specific Properties and Applications of Wavelet Families.
Filter Banks, Orthogonality, Perfect Reconstruction, and Daubechies Wavelets (DB2, DB4, DB6, etc.): See Chapter 8 Perfect Reconstruction Quadrature Mirror Filters (PRQMFs).
Multi-Resolution Convolution See Chapter 2 The CWT step-by-step.
Thanks again for your blog and I hope my comments and other resources are of value!
Best Wishes,
D. Lee Fugal
Thanks for writing this blog and sharing it. Would you recommend introductory reading on Wavelet Transform and properties?
Shahram
https://ortenga.com/

A bit more comprehensive is http://users.rowan.edu/~polikar/WAVELETS/WTtutorial.html (if your eyes can handle it :) ).
Or the book http://www.conceptualwavelets.com/index.html. I think the first chapters are available online. Sorry, I don't get the links to work... hope this helps anyway!
Vincent

Information on the book Conceptual Wavelets by D. Lee Fugal can be found at:
http://conceptualwavelets.com/
Lee, a friend of mine, also teaches a wavelets class at:
http://www.aticourses.com/wavelets_conceptual_practical_approach.htm
hi
im farhad
hoe are you?
Do you have the program MATLAB code filter banks?
naserizadehfarhad@gmail.com

Nice Article. I never saw wavelet theory but did study filter banks in great depth as they are very useful. I didn't follow exactly all the mathematical derivation, but I can see that you are expressing the basic filter bank (and all the rest that follow) with a filter and then a downsampling. In practice this is never done this way, usually you use the Noble equations to first downsample and then filter with a modified filter so you don't compute values that will be discarded. Does the derivation of the Dilation equation hold in that case or it gets terribly complicated to apply it?
Thanks!!
Agustin
correct me if I'm wrong, but I think the Noble identities cannot be used in general when we first apply the filter and then the downsampling, or vice versa for upsampling. For perfect reconstruction, we need the information of the odd samples, too!
But in a practical implementation you don't have to discard any samples, you only compute the ones you need. This means you compute $(1.9)$ only for $j=0, 2, 4, ...$.
Hi,
Is there any article that explains the content of wavelet co-efficients?
FFT gives frequency compenents and its amplitudes .
Not to sure ho w to interpret Freq, Amplitude and time related aspects from wavelets? What exactly does co-efficients 0mean? My requirement is from a signals get DWT co-efficients (10 point - 2 power 10 frequencies?) , calcualte average power in each level (10 levels) . I get 10 x 1 matrix. This matrix I need to use as feature vector for my Machine learing classification. I feel I am missign something as I am novice to wavelets. Is there any white paper that explains the content of wavelet co-effcients in an intutive way?
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:





